
Medidas de frecuencia de enfermedad
Índice de contenidos
Proporción - Razón - Tasa
La epidemiología tiene entre uno de sus objetivos primordiales el estudio de la distribución y los determinantes de las diferentes enfermedades. La cuantificación y la medida de la enfermedad o de otras variables de interés son elementos fundamentales para formular y testar hipótesis, así como para permitir comparar las frecuencias de enfermedad entre diferentes poblaciones o entre personas con o sin una exposición o característica dentro de una población determinada.
La medida más elemental de frecuencia de una enfermedad, o de cualquier otro evento en general, es el número de personas que la padecen o lo presentan (por ejemplo, el número de pacientes con hipertensión arterial, el número de fallecidos por accidentes de tráfico o el número de pacientes con algún tipo de cáncer en los que se ha registrado una recidiva). Sin embargo, dicha medida por sí sola carece de utilidad para determinar la importancia de un problema de salud determinado, pues debe referirse siempre al tamaño de la población de donde provienen los casos y al periodo de tiempo en el cual estos fueron identificados. Para este propósito, en epidemiología suele trabajarse con diferentes tipos de fracciones que permiten cuantificar correctamente el impacto de una determinada enfermedad:
- Proporción: es un cociente en el que el numerador está incluido en el denominador. Por ejemplo, si en una población de 25.000 habitantes se diagnostican 1.500 pacientes con diabetes, la proporción de diabetes en esa población es de 1.500/25.000 = 0.06 (6%). El valor de una proporción puede variar así de 0 a 1, y suele expresarse como un porcentaje.
- Razón: En este cociente el numerador no forma parte del denominador. En el ejemplo anterior, la razón entre la población con diabetes y la población no diabética es de 1.500/23.500 = 3/47 =0,064. Cuando, como en el caso del ejemplo, la razón se calcula entre la probabilidad de que ocurra un evento y la probabilidad de que éste no ocurra, la razón recibe también el nombre de odds. En el ejemplo, la odds de diabetes es de 0,06, es decir, en el área de estudio por cada 1/0,064 = 16,7 pacientes no diabéticos hay 1 que sí lo es.
El valor de una odds puede ir de 0 a infinito. El valor 0 corresponde al caso en que la enfermedad nunca ocurre, mientras que el valor infinito correspondería teóricamente a una enfermedad que esté siempre presente. En realidad, una proporción y una odds miden el mismo evento pero en escalas diferentes, y pueden relacionarse mediante las fórmulas siguientes:
|
|
|
- Tasa: El concepto de tasa es similar al de una proporción, con la diferencia de que las tasas llevan incorporado el concepto de tiempo. El numerador lo constituye la frecuencia absoluta de casos del problema a estudiar. A su vez, el denominador está constituido por la suma de los períodos individuales de riesgo a los que han estado expuestos los sujetos susceptibles de la población a estudio. De su cálculo se desprende la velocidad con que se produce el cambio de una situación clínica a otra.
En epidemiología, las medidas de frecuencia de enfermedad más comúnmente utilizadas se engloban en dos categorías: Prevalencia eIncidencia.
Prevalencia
]Como todas las proporciones, la prevalencia no tiene dimensión y nunca toma valores menores de 0 ó mayores de 1, siendo frecuente expresarla en términos de porcentaje, en tanto por ciento, tanto por mil,... en función de la “rareza” de la enfermedad estudiada. La prevalencia de un problema de salud en una comunidad determinada suele estimarse a partir de estudios transversales para determinar su importancia en un momento concreto, y no con fines predictivos. Además, es evidente que el cálculo de la prevalencia será especialmente apropiado para la medición de procesos de carácter prolongado, pero no tendrá mucho sentido para valorar la importancia de otros fenómenos de carácter más momentáneo (accidentes de tráfico, apendicitis, infarto de miocardio,...).
Otra medida de prevalencia utilizada en epidemiología, aunque no con tanta frecuencia, es la llamada prevalencia de periodo, calculada como la proporción de personas que han presentado la enfermedad en algún momento a lo largo de un periodo de tiempo determinado (por ejemplo, la prevalencia de cáncer en España en los últimos 5 años). El principal problema que plantea el cálculo de este índice es que la población total a la que se refiere puede haber cambiado durante el periodo de estudio. Normalmente, la población que se toma como denominador corresponde al punto medio del periodo considerado. Un caso especial de esta prevalencia de periodo, pero que presenta importantes dificultades para su cálculo, es la llamada prevalencia de vida, que trata de estimar la probabilidad de que un individuo desarrolle una enfermedad en algún momento a lo largo de su existencia.
![]()
Para ilustrar su cálculo, consideremos el siguiente ejemplo: en una muestra de 270 habitantes aleatoriamente seleccionada de una población de 65 y más años se objetivó que 111 presentaban obesidad (IMC³30). En este caso, la prevalencia de obesidad en ese grupo de edad y en esa población sería de:
![]()
Incidencia
La incidencia se define como el número de casos nuevos de una enfermedad que se desarrollan en una población durante un período de tiempo determinado. Hay dos tipos de medidas de incidencia: la incidencia acumulada y la tasa de incidencia, también denominada densidad de incidencia.
La incidencia acumulada ( IA) es la proporción de individuos sanos que desarrollan la enfermedad a lo largo de un período de tiempo concreto. Se calcula según:
Se calcula según:
![]()
La incidencia acumulada proporciona una estimación de la probabilidad o el riesgo de que un individuo libre de una determinada enfermedad la desarrolle durante un período especificado de tiempo. Como cualquier proporción, suele venir dada en términos de porcentaje. Además, al no ser una tasa, es imprescindible que se acompañe del periodo de observación para poder ser interpretada.
Por ejemplo: Durante un período de 6 años se siguió a 431 varones entre 40 y 59 años sanos, con colesterol sérico normal y tensión arterial normal, para detectar la presencia de cardiopatía isquémica, registrándose al final del período l0 casos de cardiopatía isquémica. La incidencia acumulada en este caso sería:
|
|
en seis años |
La incidencia acumulada asume que la población entera a riesgo al principio del estudio ha sido seguida durante todo un período de tiempo determinado para observar si se desarrollaba la enfermedad objeto del estudio. Sin embargo, en la realidad lo que sucede es que:
-
Las personas objeto de la investigación entran en el estudio en diferentes momentos en el tiempo.
-
El seguimiento de dichos sujetos objeto de la investigación no es uniforme ya que de algunos no se obtiene toda la información.
-
Por otra parte, algunos pacientes abandonan el estudio y sólo proporcionan un seguimiento limitado a un período corto de tiempo.
Para poder tener en consideración estas variaciones de seguimiento existentes en el tiempo, una primera aproximación sería limitar el cálculo de la incidencia acumulada al período de tiempo durante el cual la población entera proporcionase información. Esto de todos modos haría que perdiésemos información adicional del seguimiento disponible en alguna de las personas incluidas. La estimación más precisa es la que utiliza toda la información disponible es la denominada tasa de incidencia o densidad de incidencia (DI). Se calcula como el cociente entre el número de casos nuevos de una enfermedad ocurridos durante el periodo de seguimiento y la suma de todos los tiempos individuales de observación:
![]()
El total de personas-tiempo de observación (suma de los tiempos individuales de observación) es la suma de los períodos de tiempo en riesgo de contraer la enfermedad correspondiente a cada uno de los individuos de la población. La suma de los períodos de tiempo del denominador se mide preferentemente en años y se conoce como tiempo en riesgo. El tiempo en riesgo para cada individuo objeto de estudio es el tiempo durante el cual permanece en la población de estudio y se encuentra libre de la enfermedad, y por lo tanto en riesgo de contraerla.
La densidad de incidencia no es por lo tanto una proporción, sino una tasa, ya que el denominador incorpora la dimensión tiempo. Su valor no puede ser inferior a cero pero no tiene límite superior.
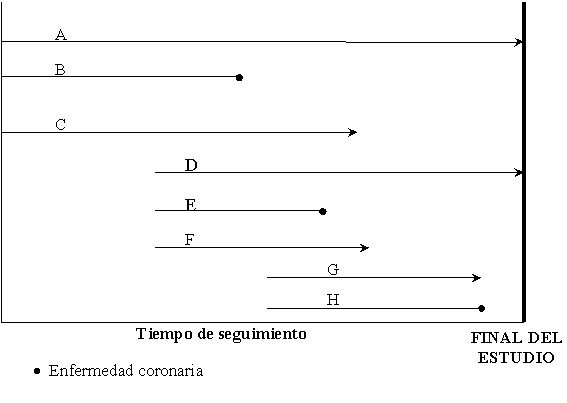
Para ilustrar su cálculo consideremos el siguiente ejemplo: En un estudio de seguimiento durante 20 años de tratamiento hormonal en 8 mujeres postmenopáusicas se observó que se presentaron 3 casos de enfermedad coronaria. Con estos datos, la incidencia acumulada sería de un 3/8 = 0,375 Þ 37,5% durante los 20 años de seguimiento. Sin embargo, tal y como se muestra en la Figura 1, el tiempo de seguimiento no es el mismo para todas las pacientes. Mientras que, por ejemplo, la paciente A ha sido observada durante todo el periodo, la paciente D ha comenzado el tratamiento más tarde, una vez comenzada la investigación, y ha sido seguida sólo durante 15 años. En otros casos, como la paciente C, han abandonado el tratamiento antes de finalizar el estudio sin presentar ninguna afección coronaria. En total se obtienen 84 personas-año de observación. La tasa de incidencia resultó por tanto ser igual a:
|
|
personas por año |
Esto es, la densidad de incidencia de enfermedad coronaria en esa población es de 3,6 nuevos casos por cada 100 personas-año de seguimiento.
La elección de una de las medidas de incidencia (incidencia acumulada o densidad de incidencia) dependerá, además del objetivo que se persiga, de las características de la enfermedad que se pretende estudiar. Así, la incidencia acumulada se utilizará generalmente cuando la enfermedad tenga un periodo de latencia corto, recurriéndose a la densidad de incidencia en el caso de enfermedades crónicas y con un periodo de latencia mayor. En cualquier caso, debe tenerse en cuenta que la utilización de la densidad de incidencia como medida de frecuencia de una enfermedad está sujeta a las siguientes condiciones:
-
El riesgo de contraer la enfermedad es constante durante todo el periodo de seguimiento. Si esto no se cumple y, por ejemplo, se estudia una enfermedad con un periodo de incubación muy largo, el periodo de observación debe dividirse en varios subperiodos.
-
La tasa de incidencia entre los casos que completan o no el seguimiento es similar. En caso contrario se obtendría un resultado sesgado.
-
El denominador es adecuado a la historia de la enfermedad.
Además, en el cálculo de cualquier medida de incidencia han de tenerse en consideración otros aspectos. En primer lugar, no deben incluirse en el denominador casos prevalentes o sujetos que no estén en condiciones de padecer la enfermedad a estudio. El denominador sólo debe incluir a aquellas personas en riesgo de contraer la enfermedad (por ejemplo, la incidencia de cáncer de próstata deberá calcularse en relación a la población masculina en una comunidad y no sobre la población total), aunque también es cierto que en problemas poco frecuentes la inclusión de casos prevalentes no cambiará mucho el resultado. En segundo lugar, además, es importante aclarar, cuando la enfermedad pueda ser recurrente, si el numerador se refiere a casos nuevos o a episodios de una misma patología.
Relación entre incidencia y prevalencia
Prevalencia e incidencia son conceptos a su vez muy relacionados. La prevalencia depende de la incidencia y de la duración de la enfermedad. Si la incidencia de una enfermedad es baja pero los afectados tienen la enfermedad durante un largo período de tiempo, la proporción de la población que tenga la enfermedad en un momento dado puede ser alta en relación con su incidencia. Inversamente, si la incidencia es alta y la duración es corta, ya sea porque se recuperan pronto o fallecen, la prevalencia puede ser baja en relación a la incidencia de dicha patología. Por lo tanto, los cambios de prevalencia de un momento a otro pueden ser resultado de cambios en la incidencia, cambios en la duración de la enfermedad o ambos.
Esta relación entre incidencia y prevalencia puede expresarse matemáticamente de un modo bastante sencillo. Si se asume que las circunstancias de la población son estables, entendiendo por estable que la incidencia de la enfermedad haya permanecido constante a lo largo del tiempo, así como su duración, entonces la prevalencia tampoco variará. Así, si el número de casos prevalentes no cambia, el número de casos nuevos de la enfermedad ha de compensar a aquellos individuos que dejan de padecerla:
Nº de casos nuevos de la enfermedad = Nº de casos que se curan o fallecen (1)
Si se denota por N al total de la población y E al número de enfermos en la misma, N-E será el total de sujetos sanos en esa población. Durante un periodo de tiempo t, el número de gente que contrae la enfermedad viene dado entonces por:
|
|
(2) |
donde DI denota a la densidad de incidencia.
Por otro lado, el número de enfermos que se curan o fallecen en ese periodo puede calcularse como
|
|
(3) |
donde D es la duración media de la enfermedad objeto de estudio.
Combinando (2) y (3) en (1) se obtiene que:
|
|
(4) |
El cociente E/N-E es el cociente entre los individuos enfermos y los no enfermos, o equivalentemente, entre la prevalencia y su complementario, P/1-P (lo que habíamos denominado odds), de modo que la expresión (4) puede escribirse equivalentemente como:
|
|
En el caso además en el que la prevalencia de la enfermedad en la población sea baja, la cantidad 1 - P es aproximadamente igual a 1 y la expresión (5) quedaría finalmente:
|
|
(6) |
Es decir, si se asume que las circunstancias de la población son estables y la enfermedad es poco frecunente, la prevalencia es proporcional al producto de la densidad de incidencia (DI) y el promedio de duración de la enfermedad (D).
De las consideraciones anteriores se deduce que la prevalencia carece de utilidad para confirmar hipótesis etiológicas, por lo que resulta más adecuado trabajar con casos incidentes. Los estudios de prevalencia pueden obtener asociaciones que reflejen los determinantes de la supervivencia y no las causas de la misma, conduciendo a conclusiones erróneas. No obstante, su relación con la incidencia permite que en ocasiones pueda utilizarse como una buena aproximación del riesgo para evaluar la asociación entre las causas y la enfermedad. También es cierto que en otras aplicaciones distintas a la investigación etiológica, como en la planificación de recursos o las prestaciones sanitarias, la prevalencia puede ser una mejor medida que la incidencia ya que nos permite conocer la magnitud global del problema.
Anexo
Bibliografía
- Kark SL. Epidemiology and community medicine. Nueva York: Appleton-Century-Crofts; 1975. p.19-21.
- Kleimbaum D, Kupper I, Morgenstern H. Epidemiologic Research. Belmont: Lifetime Learning Publications; 1982.
- Mausner J, Kramer S. Epidemiology: an introductory text. 2ª ed. Filadelfia: WB Saunders Company; 1985.
- Rothman KJ. Modern Epidemiology. Boston: Little, Brown & Co; 1986.
- Colimón KM. Fundamentos de epidemiología. 2ª ed. Madrid: Díaz de Santos; 1990.
- Argimón Pallás JM, Jiménez Villa J. Métodos de Investigación Clínica y Epidemiológica. 2ª ed. Madrid: Harcourt; 2000.
- Tapia Granados JA. Medidas de prevalencia y relación incidencia-prevalencia. Med Clin (Barc) 1995; 105: 216-218. [Medline]
- Tapia Granados JA. Incidencia: concepto, terminología y análisis dimensional. Med Clin (Barc) 1994; 103: 140-142. [Medline]
- Freeman J, Hutchinson GB. Prevalence, incidente and duration. Am J Epidemiol 1980; 112: 707-723. [Medline]
Autores
(1)Unidad de Epidemiología Clínica y Bioestadística. Complexo Hospitalario-Universitario Juan Canalejo. A Coruña (España).
(2) Servicio de nefrología. Complexo Hospitalario Universitario de A Coruña (España).
Medidas de frecuencia de enfermedad
Índice de contenidos
Proporción - Razón - Tasa
La epidemiología tiene entre uno de sus objetivos primordiales el estudio de la distribución y los determinantes de las diferentes enfermedades. La cuantificación y la medida de la enfermedad o de otras variables de interés son elementos fundamentales para formular y testar hipótesis, así como para permitir comparar las frecuencias de enfermedad entre diferentes poblaciones o entre personas con o sin una exposición o característica dentro de una población determinada.
La medida más elemental de frecuencia de una enfermedad, o de cualquier otro evento en general, es el número de personas que la padecen o lo presentan (por ejemplo, el número de pacientes con hipertensión arterial, el número de fallecidos por accidentes de tráfico o el número de pacientes con algún tipo de cáncer en los que se ha registrado una recidiva). Sin embargo, dicha medida por sí sola carece de utilidad para determinar la importancia de un problema de salud determinado, pues debe referirse siempre al tamaño de la población de donde provienen los casos y al periodo de tiempo en el cual estos fueron identificados. Para este propósito, en epidemiología suele trabajarse con diferentes tipos de fracciones que permiten cuantificar correctamente el impacto de una determinada enfermedad:
- Proporción: es un cociente en el que el numerador está incluido en el denominador. Por ejemplo, si en una población de 25.000 habitantes se diagnostican 1.500 pacientes con diabetes, la proporción de diabetes en esa población es de 1.500/25.000 = 0.06 (6%). El valor de una proporción puede variar así de 0 a 1, y suele expresarse como un porcentaje.
- Razón: En este cociente el numerador no forma parte del denominador. En el ejemplo anterior, la razón entre la población con diabetes y la población no diabética es de 1.500/23.500 = 3/47 =0,064. Cuando, como en el caso del ejemplo, la razón se calcula entre la probabilidad de que ocurra un evento y la probabilidad de que éste no ocurra, la razón recibe también el nombre de odds. En el ejemplo, la odds de diabetes es de 0,06, es decir, en el área de estudio por cada 1/0,064 = 16,7 pacientes no diabéticos hay 1 que sí lo es.
El valor de una odds puede ir de 0 a infinito. El valor 0 corresponde al caso en que la enfermedad nunca ocurre, mientras que el valor infinito correspondería teóricamente a una enfermedad que esté siempre presente. En realidad, una proporción y una odds miden el mismo evento pero en escalas diferentes, y pueden relacionarse mediante las fórmulas siguientes:
|
|
|
- Tasa: El concepto de tasa es similar al de una proporción, con la diferencia de que las tasas llevan incorporado el concepto de tiempo. El numerador lo constituye la frecuencia absoluta de casos del problema a estudiar. A su vez, el denominador está constituido por la suma de los períodos individuales de riesgo a los que han estado expuestos los sujetos susceptibles de la población a estudio. De su cálculo se desprende la velocidad con que se produce el cambio de una situación clínica a otra.
En epidemiología, las medidas de frecuencia de enfermedad más comúnmente utilizadas se engloban en dos categorías: Prevalencia eIncidencia.
Prevalencia
]Como todas las proporciones, la prevalencia no tiene dimensión y nunca toma valores menores de 0 ó mayores de 1, siendo frecuente expresarla en términos de porcentaje, en tanto por ciento, tanto por mil,... en función de la “rareza” de la enfermedad estudiada. La prevalencia de un problema de salud en una comunidad determinada suele estimarse a partir de estudios transversales para determinar su importancia en un momento concreto, y no con fines predictivos. Además, es evidente que el cálculo de la prevalencia será especialmente apropiado para la medición de procesos de carácter prolongado, pero no tendrá mucho sentido para valorar la importancia de otros fenómenos de carácter más momentáneo (accidentes de tráfico, apendicitis, infarto de miocardio,...).
Otra medida de prevalencia utilizada en epidemiología, aunque no con tanta frecuencia, es la llamada prevalencia de periodo, calculada como la proporción de personas que han presentado la enfermedad en algún momento a lo largo de un periodo de tiempo determinado (por ejemplo, la prevalencia de cáncer en España en los últimos 5 años). El principal problema que plantea el cálculo de este índice es que la población total a la que se refiere puede haber cambiado durante el periodo de estudio. Normalmente, la población que se toma como denominador corresponde al punto medio del periodo considerado. Un caso especial de esta prevalencia de periodo, pero que presenta importantes dificultades para su cálculo, es la llamada prevalencia de vida, que trata de estimar la probabilidad de que un individuo desarrolle una enfermedad en algún momento a lo largo de su existencia.
![]()
Para ilustrar su cálculo, consideremos el siguiente ejemplo: en una muestra de 270 habitantes aleatoriamente seleccionada de una población de 65 y más años se objetivó que 111 presentaban obesidad (IMC³30). En este caso, la prevalencia de obesidad en ese grupo de edad y en esa población sería de:
![]()
Incidencia
La incidencia se define como el número de casos nuevos de una enfermedad que se desarrollan en una población durante un período de tiempo determinado. Hay dos tipos de medidas de incidencia: la incidencia acumulada y la tasa de incidencia, también denominada densidad de incidencia.
La incidencia acumulada ( IA) es la proporción de individuos sanos que desarrollan la enfermedad a lo largo de un período de tiempo concreto. Se calcula según:
Se calcula según:
![]()
La incidencia acumulada proporciona una estimación de la probabilidad o el riesgo de que un individuo libre de una determinada enfermedad la desarrolle durante un período especificado de tiempo. Como cualquier proporción, suele venir dada en términos de porcentaje. Además, al no ser una tasa, es imprescindible que se acompañe del periodo de observación para poder ser interpretada.
Por ejemplo: Durante un período de 6 años se siguió a 431 varones entre 40 y 59 años sanos, con colesterol sérico normal y tensión arterial normal, para detectar la presencia de cardiopatía isquémica, registrándose al final del período l0 casos de cardiopatía isquémica. La incidencia acumulada en este caso sería:
|
|
en seis años |
La incidencia acumulada asume que la población entera a riesgo al principio del estudio ha sido seguida durante todo un período de tiempo determinado para observar si se desarrollaba la enfermedad objeto del estudio. Sin embargo, en la realidad lo que sucede es que:
-
Las personas objeto de la investigación entran en el estudio en diferentes momentos en el tiempo.
-
El seguimiento de dichos sujetos objeto de la investigación no es uniforme ya que de algunos no se obtiene toda la información.
-
Por otra parte, algunos pacientes abandonan el estudio y sólo proporcionan un seguimiento limitado a un período corto de tiempo.
Para poder tener en consideración estas variaciones de seguimiento existentes en el tiempo, una primera aproximación sería limitar el cálculo de la incidencia acumulada al período de tiempo durante el cual la población entera proporcionase información. Esto de todos modos haría que perdiésemos información adicional del seguimiento disponible en alguna de las personas incluidas. La estimación más precisa es la que utiliza toda la información disponible es la denominada tasa de incidencia o densidad de incidencia (DI). Se calcula como el cociente entre el número de casos nuevos de una enfermedad ocurridos durante el periodo de seguimiento y la suma de todos los tiempos individuales de observación:
![]()
El total de personas-tiempo de observación (suma de los tiempos individuales de observación) es la suma de los períodos de tiempo en riesgo de contraer la enfermedad correspondiente a cada uno de los individuos de la población. La suma de los períodos de tiempo del denominador se mide preferentemente en años y se conoce como tiempo en riesgo. El tiempo en riesgo para cada individuo objeto de estudio es el tiempo durante el cual permanece en la población de estudio y se encuentra libre de la enfermedad, y por lo tanto en riesgo de contraerla.
La densidad de incidencia no es por lo tanto una proporción, sino una tasa, ya que el denominador incorpora la dimensión tiempo. Su valor no puede ser inferior a cero pero no tiene límite superior.
Para ilustrar su cálculo consideremos el siguiente ejemplo: En un estudio de seguimiento durante 20 años de tratamiento hormonal en 8 mujeres postmenopáusicas se observó que se presentaron 3 casos de enfermedad coronaria. Con estos datos, la incidencia acumulada sería de un 3/8 = 0,375 Þ 37,5% durante los 20 años de seguimiento. Sin embargo, tal y como se muestra en la Figura 1, el tiempo de seguimiento no es el mismo para todas las pacientes. Mientras que, por ejemplo, la paciente A ha sido observada durante todo el periodo, la paciente D ha comenzado el tratamiento más tarde, una vez comenzada la investigación, y ha sido seguida sólo durante 15 años. En otros casos, como la paciente C, han abandonado el tratamiento antes de finalizar el estudio sin presentar ninguna afección coronaria. En total se obtienen 84 personas-año de observación. La tasa de incidencia resultó por tanto ser igual a:
|
|
personas por año |
Esto es, la densidad de incidencia de enfermedad coronaria en esa población es de 3,6 nuevos casos por cada 100 personas-año de seguimiento.
La elección de una de las medidas de incidencia (incidencia acumulada o densidad de incidencia) dependerá, además del objetivo que se persiga, de las características de la enfermedad que se pretende estudiar. Así, la incidencia acumulada se utilizará generalmente cuando la enfermedad tenga un periodo de latencia corto, recurriéndose a la densidad de incidencia en el caso de enfermedades crónicas y con un periodo de latencia mayor. En cualquier caso, debe tenerse en cuenta que la utilización de la densidad de incidencia como medida de frecuencia de una enfermedad está sujeta a las siguientes condiciones:
-
El riesgo de contraer la enfermedad es constante durante todo el periodo de seguimiento. Si esto no se cumple y, por ejemplo, se estudia una enfermedad con un periodo de incubación muy largo, el periodo de observación debe dividirse en varios subperiodos.
-
La tasa de incidencia entre los casos que completan o no el seguimiento es similar. En caso contrario se obtendría un resultado sesgado.
-
El denominador es adecuado a la historia de la enfermedad.
Además, en el cálculo de cualquier medida de incidencia han de tenerse en consideración otros aspectos. En primer lugar, no deben incluirse en el denominador casos prevalentes o sujetos que no estén en condiciones de padecer la enfermedad a estudio. El denominador sólo debe incluir a aquellas personas en riesgo de contraer la enfermedad (por ejemplo, la incidencia de cáncer de próstata deberá calcularse en relación a la población masculina en una comunidad y no sobre la población total), aunque también es cierto que en problemas poco frecuentes la inclusión de casos prevalentes no cambiará mucho el resultado. En segundo lugar, además, es importante aclarar, cuando la enfermedad pueda ser recurrente, si el numerador se refiere a casos nuevos o a episodios de una misma patología.
Relación entre incidencia y prevalencia
Prevalencia e incidencia son conceptos a su vez muy relacionados. La prevalencia depende de la incidencia y de la duración de la enfermedad. Si la incidencia de una enfermedad es baja pero los afectados tienen la enfermedad durante un largo período de tiempo, la proporción de la población que tenga la enfermedad en un momento dado puede ser alta en relación con su incidencia. Inversamente, si la incidencia es alta y la duración es corta, ya sea porque se recuperan pronto o fallecen, la prevalencia puede ser baja en relación a la incidencia de dicha patología. Por lo tanto, los cambios de prevalencia de un momento a otro pueden ser resultado de cambios en la incidencia, cambios en la duración de la enfermedad o ambos.
Esta relación entre incidencia y prevalencia puede expresarse matemáticamente de un modo bastante sencillo. Si se asume que las circunstancias de la población son estables, entendiendo por estable que la incidencia de la enfermedad haya permanecido constante a lo largo del tiempo, así como su duración, entonces la prevalencia tampoco variará. Así, si el número de casos prevalentes no cambia, el número de casos nuevos de la enfermedad ha de compensar a aquellos individuos que dejan de padecerla:
Nº de casos nuevos de la enfermedad = Nº de casos que se curan o fallecen (1)
Si se denota por N al total de la población y E al número de enfermos en la misma, N-E será el total de sujetos sanos en esa población. Durante un periodo de tiempo t, el número de gente que contrae la enfermedad viene dado entonces por:
|
|
(2) |
donde DI denota a la densidad de incidencia.
Por otro lado, el número de enfermos que se curan o fallecen en ese periodo puede calcularse como
|
|
(3) |
donde D es la duración media de la enfermedad objeto de estudio.
Combinando (2) y (3) en (1) se obtiene que:
|
|
(4) |
El cociente E/N-E es el cociente entre los individuos enfermos y los no enfermos, o equivalentemente, entre la prevalencia y su complementario, P/1-P (lo que habíamos denominado odds), de modo que la expresión (4) puede escribirse equivalentemente como:
|
|
En el caso además en el que la prevalencia de la enfermedad en la población sea baja, la cantidad 1 - P es aproximadamente igual a 1 y la expresión (5) quedaría finalmente:
|
|
(6) |
Es decir, si se asume que las circunstancias de la población son estables y la enfermedad es poco frecunente, la prevalencia es proporcional al producto de la densidad de incidencia (DI) y el promedio de duración de la enfermedad (D).
De las consideraciones anteriores se deduce que la prevalencia carece de utilidad para confirmar hipótesis etiológicas, por lo que resulta más adecuado trabajar con casos incidentes. Los estudios de prevalencia pueden obtener asociaciones que reflejen los determinantes de la supervivencia y no las causas de la misma, conduciendo a conclusiones erróneas. No obstante, su relación con la incidencia permite que en ocasiones pueda utilizarse como una buena aproximación del riesgo para evaluar la asociación entre las causas y la enfermedad. También es cierto que en otras aplicaciones distintas a la investigación etiológica, como en la planificación de recursos o las prestaciones sanitarias, la prevalencia puede ser una mejor medida que la incidencia ya que nos permite conocer la magnitud global del problema.
Anexo
Bibliografía
- Kark SL. Epidemiology and community medicine. Nueva York: Appleton-Century-Crofts; 1975. p.19-21.
- Kleimbaum D, Kupper I, Morgenstern H. Epidemiologic Research. Belmont: Lifetime Learning Publications; 1982.
- Mausner J, Kramer S. Epidemiology: an introductory text. 2ª ed. Filadelfia: WB Saunders Company; 1985.
- Rothman KJ. Modern Epidemiology. Boston: Little, Brown & Co; 1986.
- Colimón KM. Fundamentos de epidemiología. 2ª ed. Madrid: Díaz de Santos; 1990.
- Argimón Pallás JM, Jiménez Villa J. Métodos de Investigación Clínica y Epidemiológica. 2ª ed. Madrid: Harcourt; 2000.
- Tapia Granados JA. Medidas de prevalencia y relación incidencia-prevalencia. Med Clin (Barc) 1995; 105: 216-218. [Medline]
- Tapia Granados JA. Incidencia: concepto, terminología y análisis dimensional. Med Clin (Barc) 1994; 103: 140-142. [Medline]
- Freeman J, Hutchinson GB. Prevalence, incidente and duration. Am J Epidemiol 1980; 112: 707-723. [Medline]
Autores
(1)Unidad de Epidemiología Clínica y Bioestadística. Complexo Hospitalario-Universitario Juan Canalejo. A Coruña (España).
(2) Servicio de nefrología. Complexo Hospitalario Universitario de A Coruña (España).
